Xorbits Inference:Ollama最强竞品
Xorbits Inference:Ollama最强竞品
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。其特点是部署快捷、使用简单、推理高效,并且支持多种形式的开源模型,还提供了 WebGUI 界面和 API 接口,方便用户进行模型部署和推理。
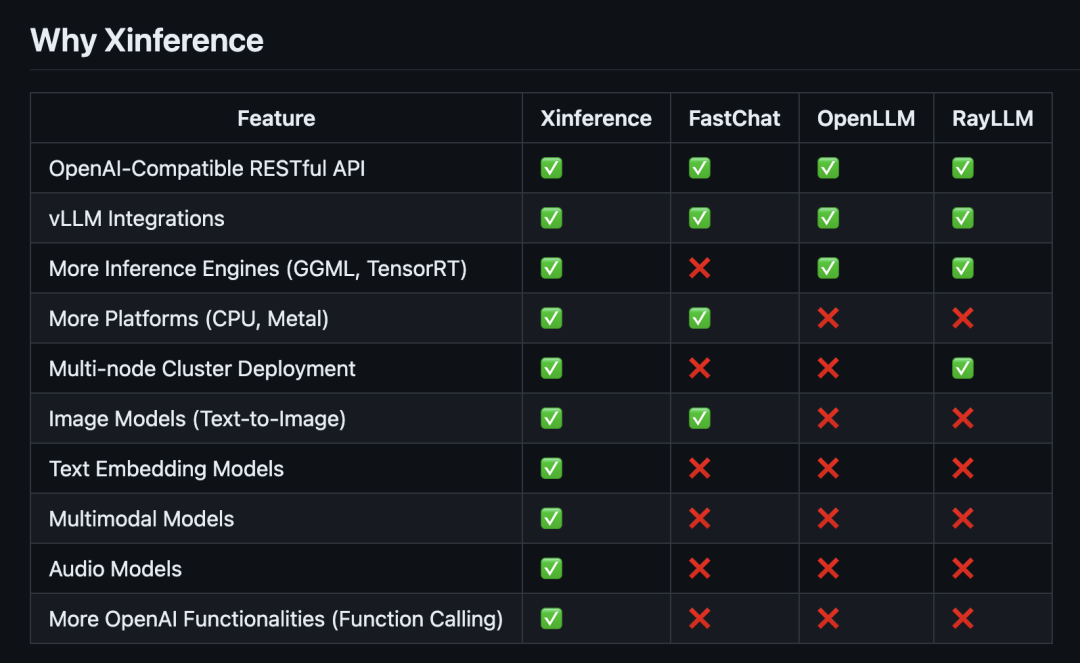
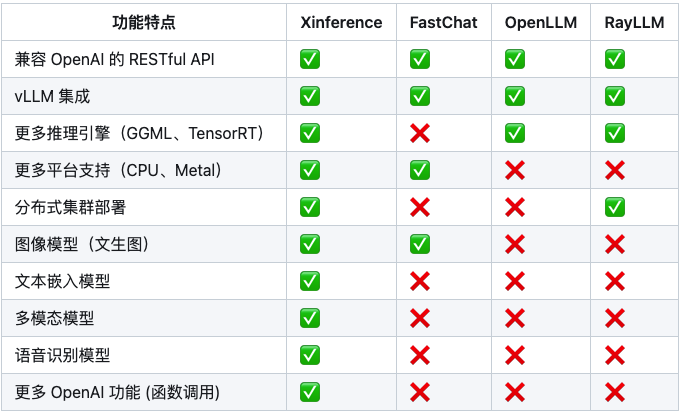
下面是 Xinference 与其他模型部署推理工具的对比:
集成知识库
它不仅仅支持大模型的部署和使用,还集成了知识库:
- FastGPT:一个基于 LLM 大模型的开源 AI 知识库构建平台。提供了开箱即用的数据处理、模型调用、RAG 检索、可视化 AI 工作流编排等能力,帮助您轻松实现复杂的问答场景。
- Dify: 一个涵盖了大型语言模型开发、部署、维护和优化的 LLMOps 平台。
- Chatbox: 一个支持前沿大语言模型的桌面客户端,支持 Windows,Mac,以及 Linux。
- RAGFlow: 是一款基于深度文档理解构建的开源 RAG 引擎。
主要功能
- 模型推理,轻而易举:大语言模型,语音识别模型,多模态模型的部署流程被大大简化。一个命令即可完成模型的部署工作。
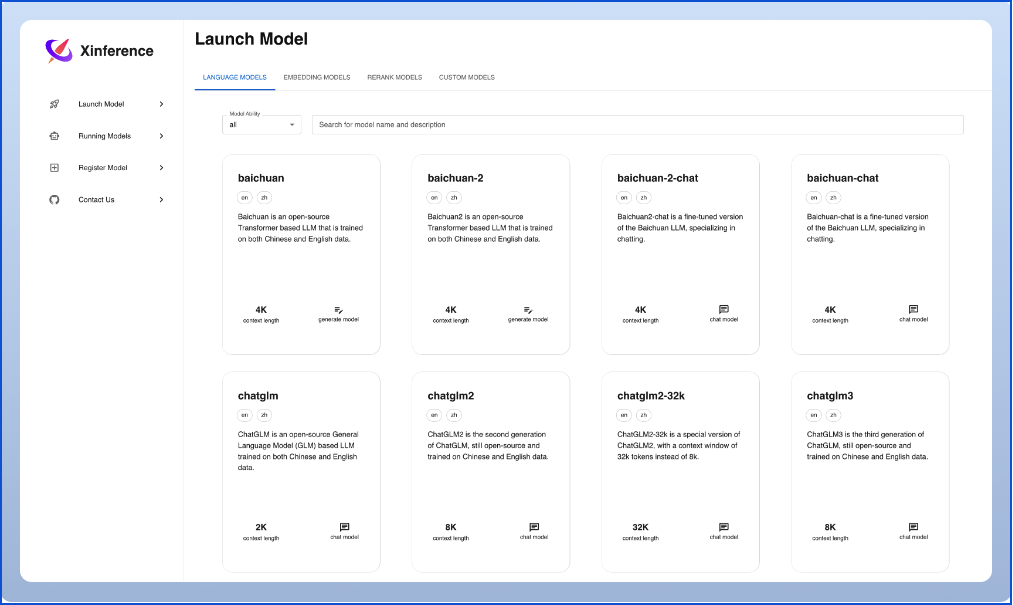
- 前沿模型,应有尽有:框架内置众多中英文的前沿大语言模型,包括 baichuan,chatglm2 等,一键即可体验!内置模型列表还在快速更新中!
- 异构硬件,快如闪电:通过 ggml,同时使用你的 GPU 与 CPU 进行推理,降低延迟,提高吞吐!
- 接口调用,灵活多样:提供多种使用模型的接口,包括 OpenAI 兼容的 RESTful API(包括 Function Calling),RPC,命令行,web UI 等等。方便模型的管理与交互。
- 集群计算,分布协同: 支持分布式部署,通过内置的资源调度器,让不同大小的模型按需调度到不同机器,充分使用集群资源。
- 开放生态,无缝对接: 与流行的三方库无缝对接,包括 LangChain,LlamaIndex,Dify,以及 Chatbox。
Xinference 部署
Docker部署
Nvidia GPU 用户可以使用Xinference Docker 镜像 启动 Xinference 服务器。在执行安装命令之前,确保你的系统中已经安装了 Docker 和 CUDA。
本地部署
使用 pip 安装 Xinference,操作如下:
pip install "xinference[all]"
要启动一个本地的 Xinference 实例,请运行以下命令:
$ xinference-local
一旦 Xinference 运行起来,你可以通过多种方式尝试它:通过网络界面、通过 cURL、通过命令行或通过 Xinference 的 Python 客户端。
这里通过网络界面来访问:http://localhost:9777