InternLM2 7B中文开源大模型的天花板
InternLM2 7B中文开源大模型的天花板

InternLM2.5采用更高效的模型结构,拥有更卓越的推理能力,能处理 1M 超长上下文、互联网搜索与信息整合等复杂任务。
InternLM2.5 目前开源了应用场景最广的轻量级 7B 版本,模型兼顾速度、效率与性能表现。模型全面增强了在复杂场景下的推理能力并支持 1M 超长上下文,能自主进行互联网搜索并从上百个网页中完成信息整合。
模型说明
目前 InternLM 2.5 系列只发布了 7B 大小的模型,接下来将开源 1.8B 和 20B 的版本。7B 为轻量级的研究和应用提供了一个轻便但性能不俗的模型,20B 模型的综合性能更为强劲,可以有效支持更加复杂的实用场景。每个规格不同模型关系如下所示:
- InternLM2.5:经历了大规模预训练的基座模型,是最推荐的在大部分应用中考虑选用的优秀基座。
- InternLM2.5-Chat: 对话模型,在 InternLM2.5 基座上经历了有监督微调和 online RLHF。InternLM2.5-Chat 面向对话交互进行了优化,具有较好的指令遵循、共情聊天和调用工具等的能力,是我们推荐直接用于下游应用的模型。
- InternLM2.5-Chat-1M: InternLM2.5-Chat-1M 支持一百万字超长上下文,并具有和 InternLM2.5-Chat 相当的综合性能表现。
模型测评
这里采用的对比模型分别是:qwen1.5-7B-Chat、ChatGLM-6b,基本都是同尺寸的模型

客观综合
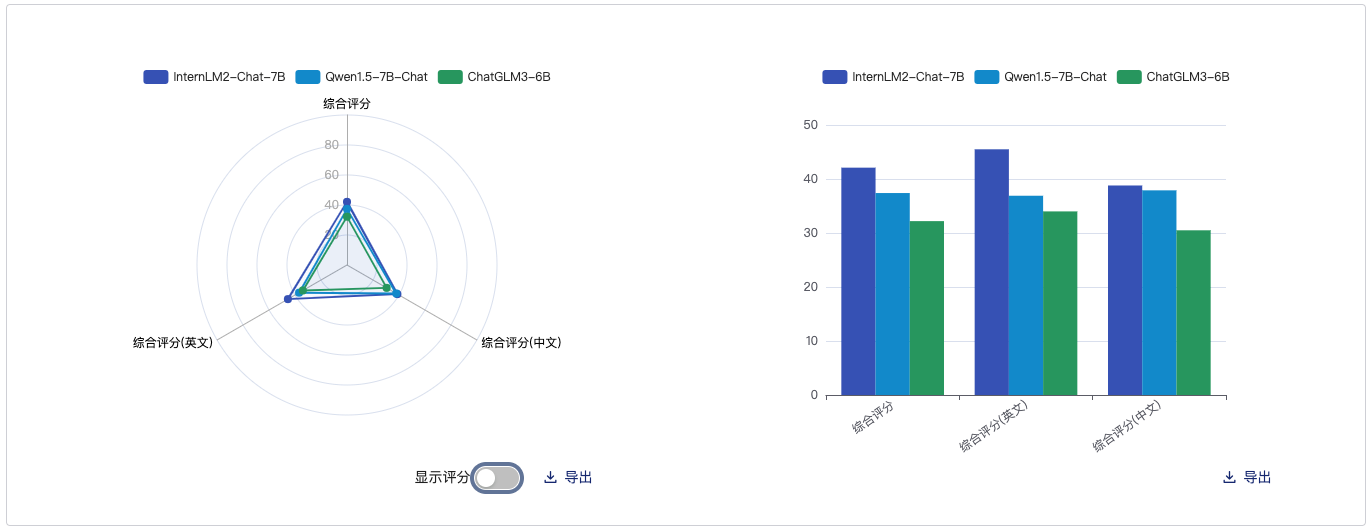
主观综合
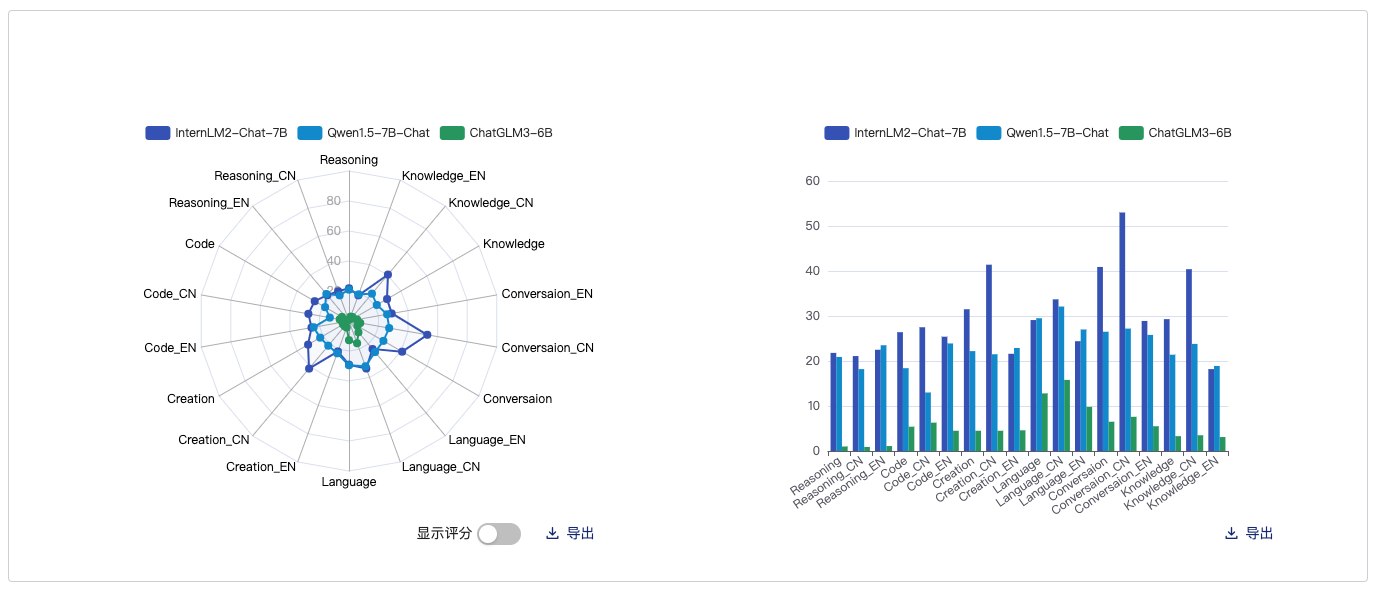
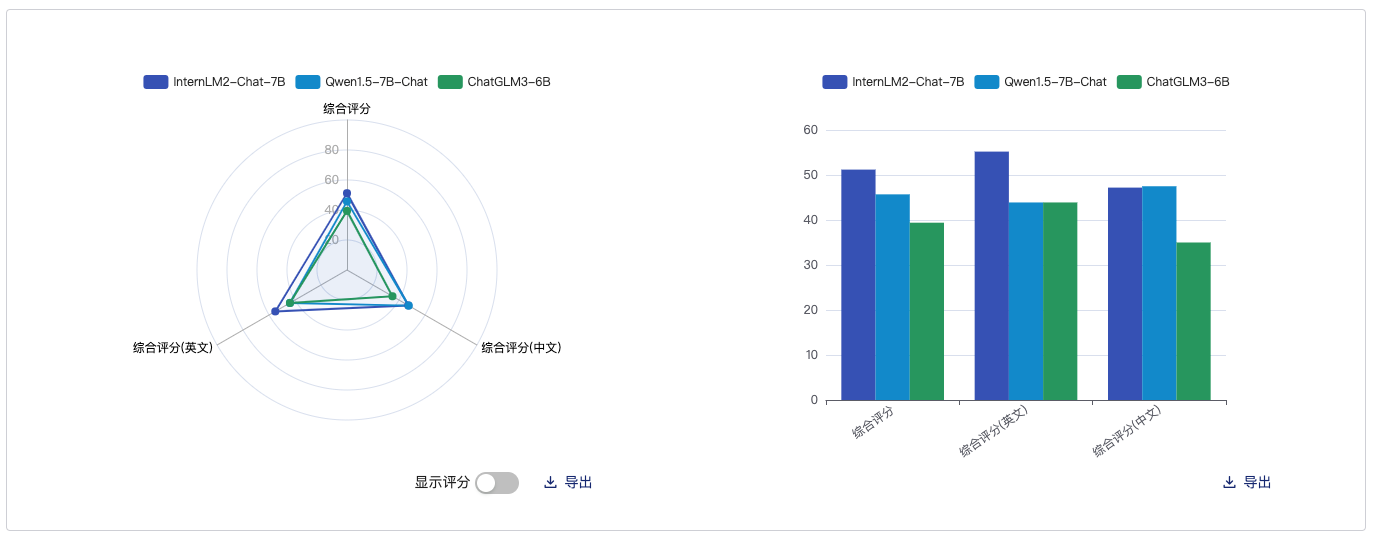
语言对比
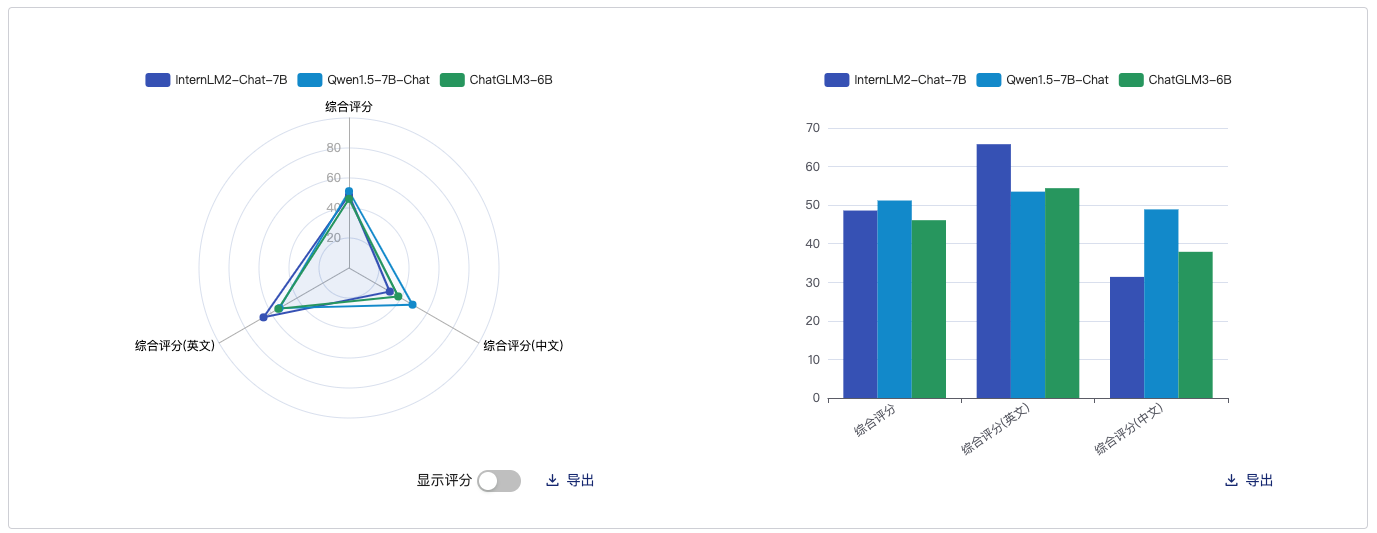
知识存储
数学代码能力
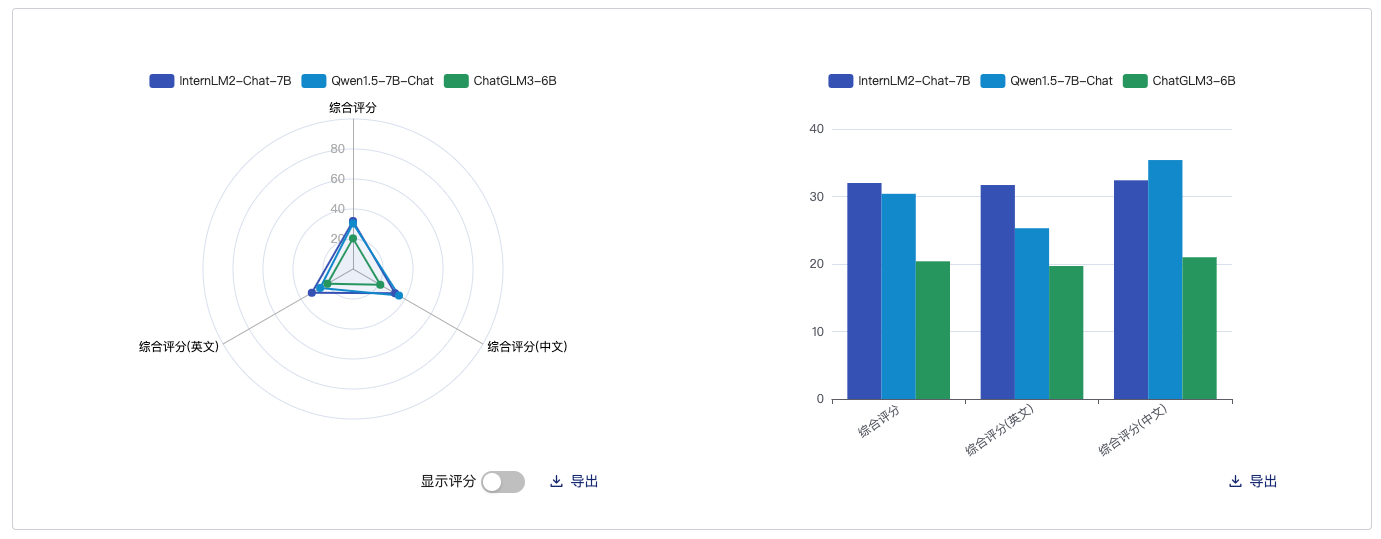
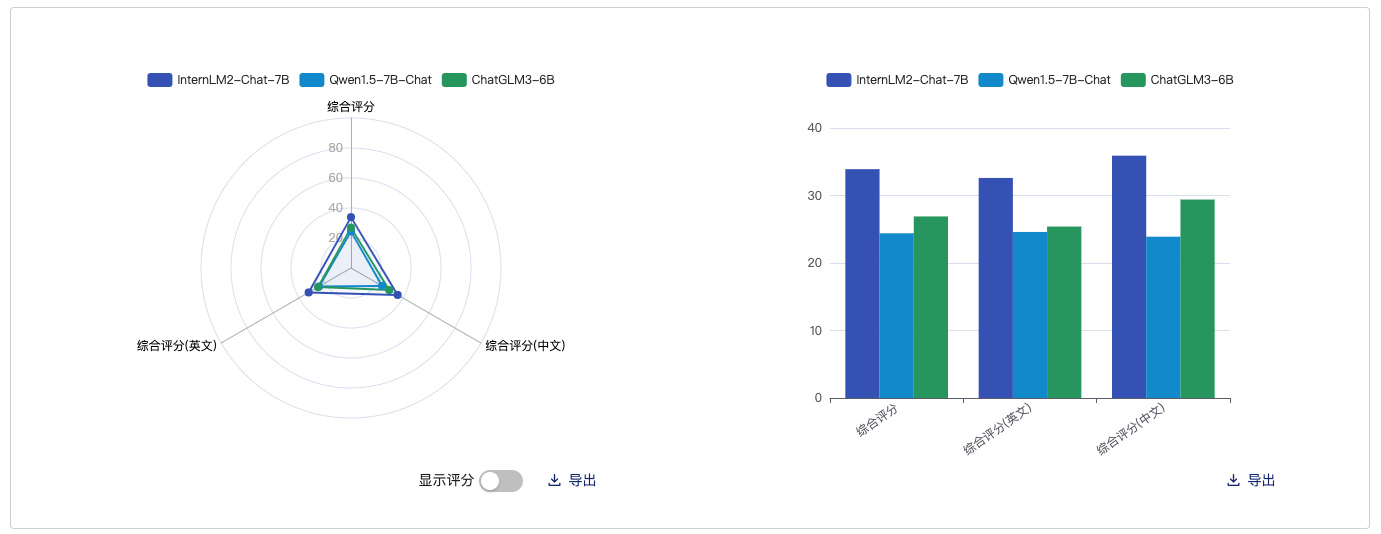
性能对比
这里使用开源评测工具 OpenCompass 在几个重要的基准测试中对 InternLM2.5 进行了评测。部分评测结果如下表所示。
基座模型
| Benchmark | InternLM2.5-7B | Llama3-8B | Yi-1.5-9B |
|---|---|---|---|
| MMLU (5-shot) | 71.6 | 66.4 | 71.6 |
| CMMLU (5-shot) | 79.1 | 51.0 | 74.1 |
| BBH (3-shot) | 70.1 | 59.7 | 71.1 |
| MATH (4-shot) | 34.0 | 16.4 | 31.9 |
| GSM8K (4-shot) | 74.8 | 54.3 | 74.5 |
| GPQA (0-shot) | 31.3 | 31.3 | 27.8 |
对话模型
| Benchmark | InternLM2.5-7B-Chat | Llama3-8B-Instruct | Gemma2-9B-IT | Yi-1.5-9B-Chat | GLM-4-9B-Chat | Qwen2-7B-Instruct |
|---|---|---|---|---|---|---|
| MMLU (5-shot) | 72.8 | 68.4 | 70.9 | 71.0 | 71.4 | 70.8 |
| CMMLU (5-shot) | 78.0 | 53.3 | 60.3 | 74.5 | 74.5 | 80.9 |
| BBH (3-shot CoT) | 71.6 | 54.4 | 68.2* | 69.6 | 69.6 | 65.0 |
| MATH (0-shot CoT) | 60.1 | 27.9 | 46.9 | 51.1 | 51.1 | 48.6 |
| GSM8K (0-shot CoT) | 86.0 | 72.9 | 88.9 | 80.1 | 85.3 | 82.9 |
| GPQA (0-shot) | 38.4 | 26.1 | 33.8 | 37.9 | 36.9 | 38.4 |
结论
这里介绍了InternLM2大型语言模型,它在主观和客观评测中表现出色。InternLM2基于超过2T的高质量预训练数据进行训练,涵盖了1.8B、7B和20B参数的模型规模,适用于多种场景。为了更好地支持长文本处理,InternLM2采用了GQA来降低推理成本,并额外训练在多达32000个上下文中。应该是同类型中文大模型的佼佼者。