Ollama v0.1.33版本试用体验
Ollama v0.1.33版本试用体验
昨天带大家一起看了Ollama v0.1.33版本的新特性,那么今天就先来体验一下吧。
启动服务
首先正常启动Ollama服务器
ollama serve
并发测试
启动完成后,同时开启两个命令窗口,使用gemma:2b模型
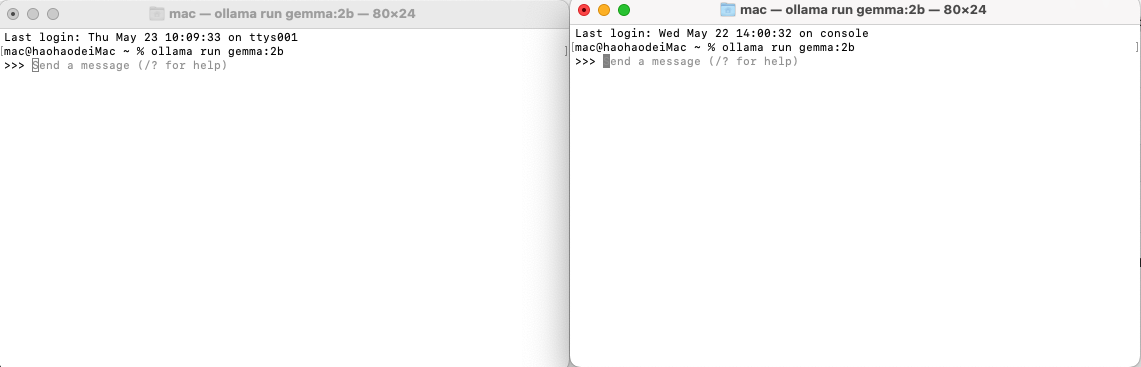
然后让它帮我写一篇关于足球的博客。
然后几乎同时启动这两个会话,但是可以看到两个会话处于串行状态,因为Ollama服务器只能并发的响应一个请求。另外一个请求必须等到前一个请求完成,后一个才能继续,
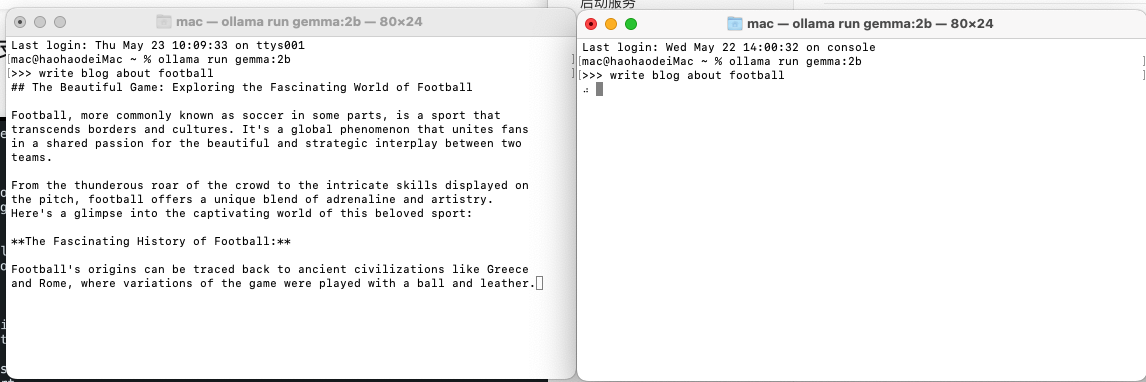
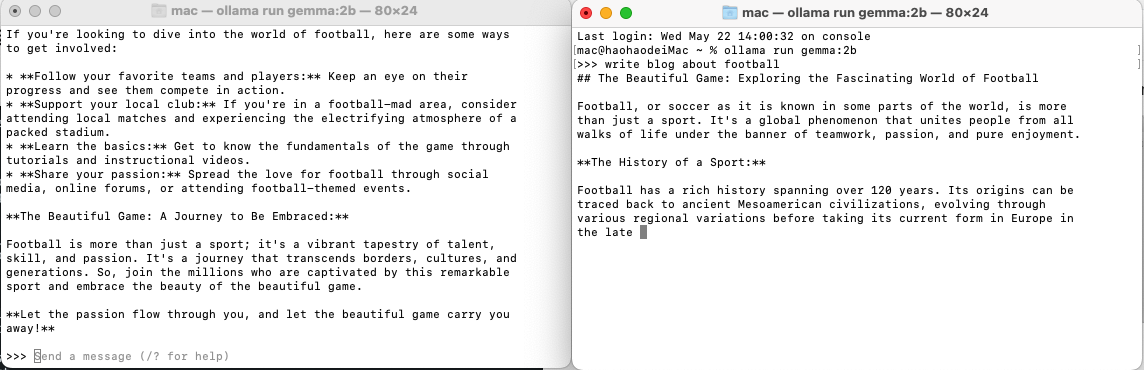
但是在最新的版本中,已经实验性的提供了并发性的支持。
并发参数的使用
我们在启动Ollama的控制台上,将启动参数 OLLAMA_NUM_PARALLEL 设为3,重新启动Ollama服务
OLLAMA_NUM_PARALLEL=3 ollama serve
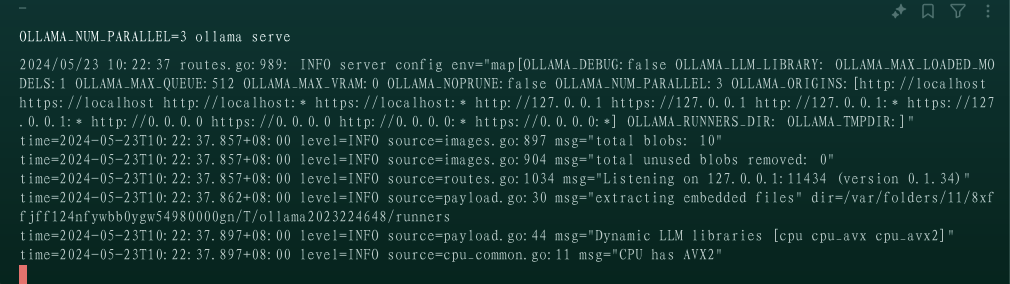
现在就可以并发的处理三个请求。
我现在同时打开四个控制台,并使用gemma:2b模型
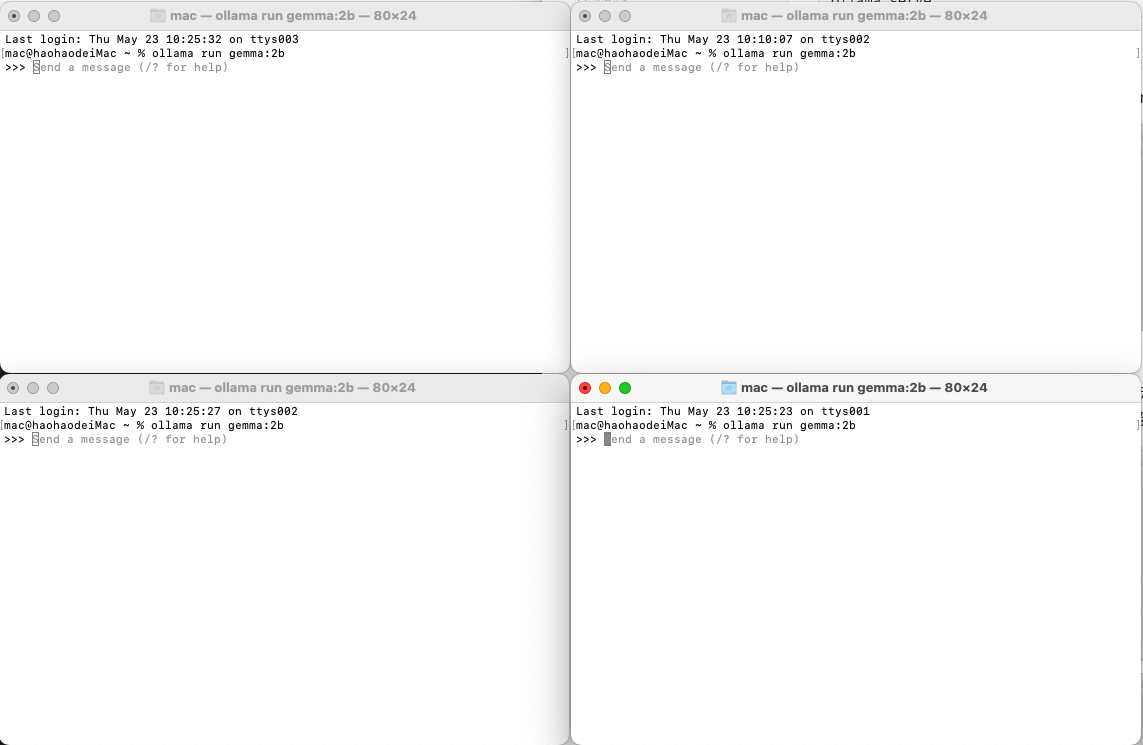
然后还是沿用上面的问题来继续进行测试,然后我几乎同时开始会话,就可以看到
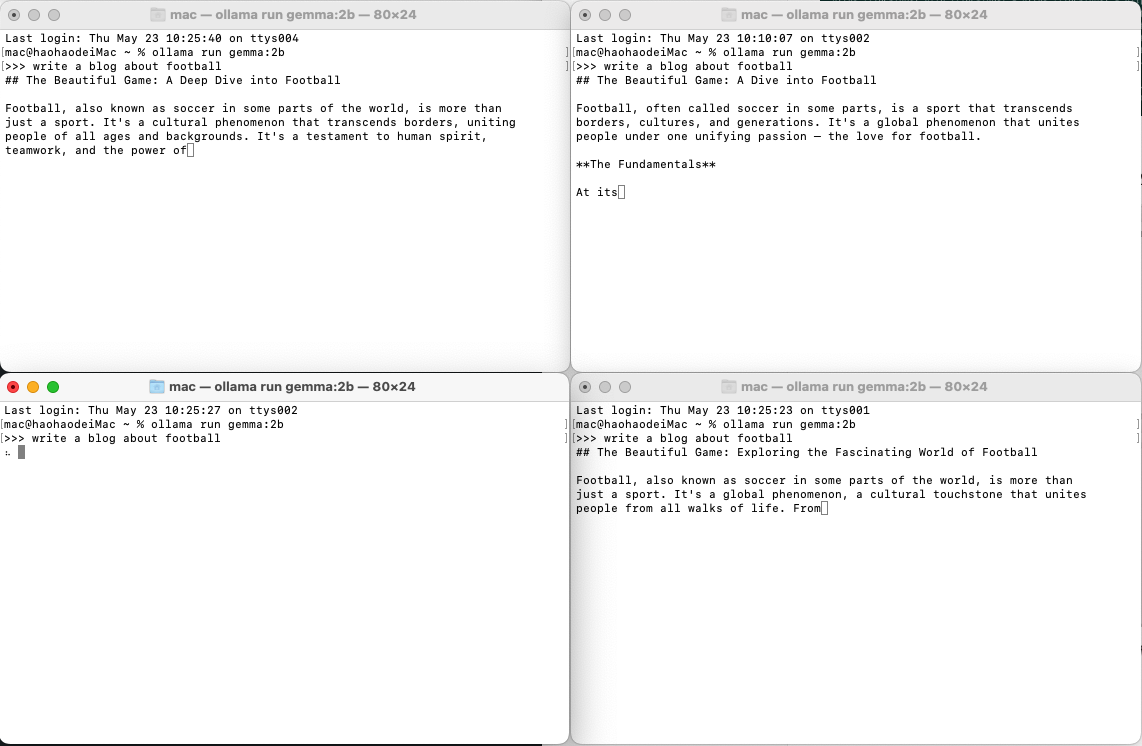
由于我开始的时间并不能完全的一致,所以可以看到除了左下角的会话没有启动之外,其他三个会话都是同步进行的。因为我这个服务设置的并发数是3。
不同模型的并发
现在我讲上面的两个会话的模型修改为ollama3,而下面的两个会话保持不变
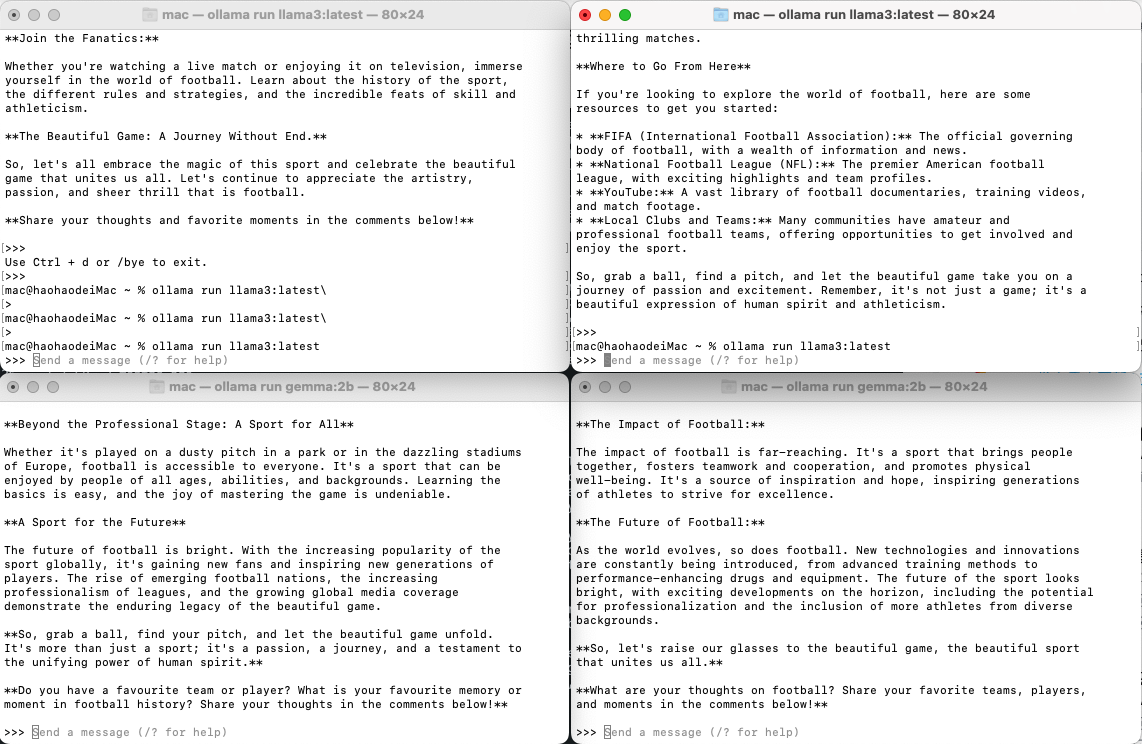
同样我也让它们编写关于足球的博客,也是同时启动。
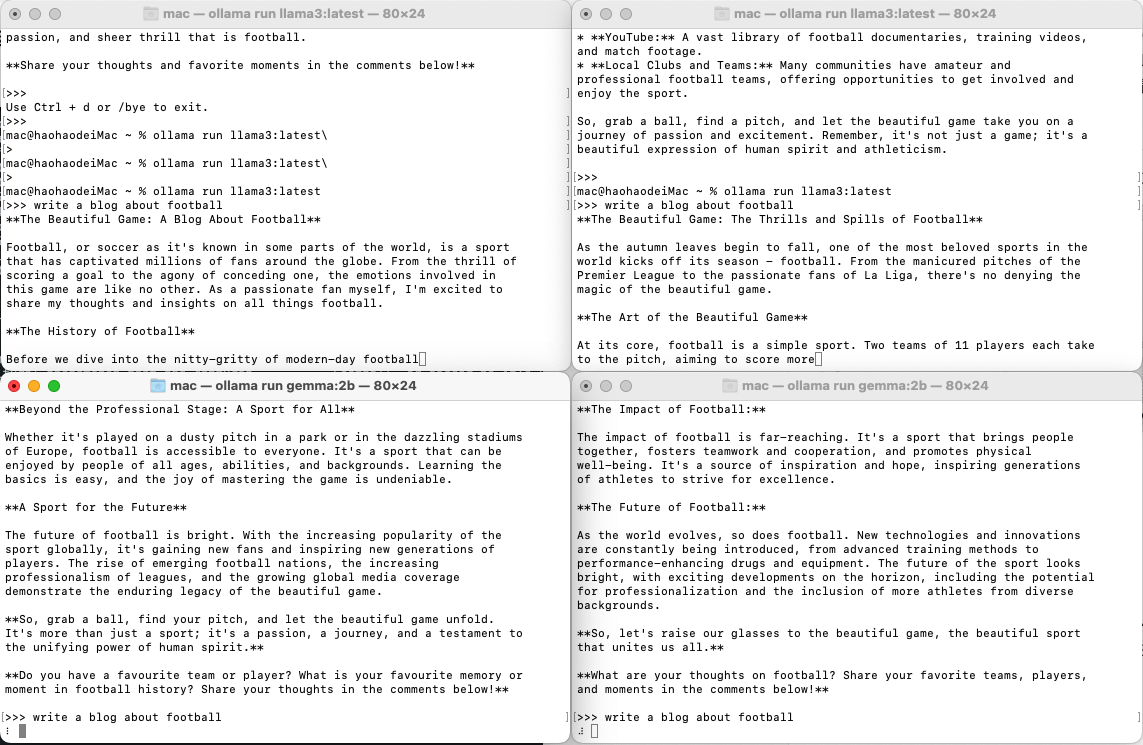
因为我们设置的并发请求数是3,而上面的两个会话使用的是ollama3模型,下面两个会话是gemmin2b。
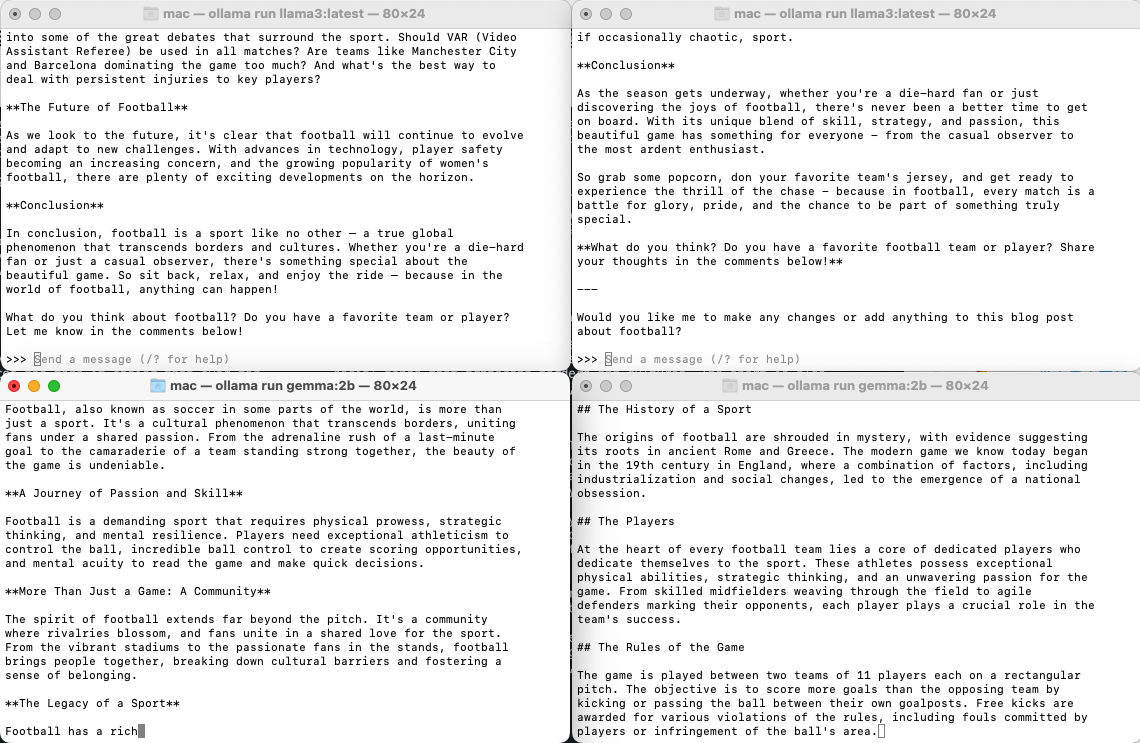
在上面两个并发请求执行完之后,下面两个会话也同时开始执行。这是因为我们只设置了最大请求数为3,但没有设置同时加载的模型数。因此ollama开始只加载了一个模型,一个模型的请求处理完成之后, 再去加载另一个模型,并执行请求。
设置同时加载模型
如果我们想要上面的四个会话都同时进行,那么我们就需要设置同时加载的模型数。
OLLAMA_NUM_PARALLEL=3 OLLAMA_MAX_LOADED_MODELS=2 ollama serve
然后再去重新对他们提问,还是同样的问题,只是模型做出了改变

然后现在就可以看到四个会话都同时开始了处理。