LLaMA-Omni:专为与 LLM 进行低延迟和高质量语音交互模型
LLaMA-Omni:专为与 LLM 进行低延迟和高质量语音交互模型
大型语言模型(LLM)已经成为强大的通用任务解决方案,能够通过对话交互帮助人们处理日常生活的各个方面。然而,对基于文本的交互的过度依赖极大地限制了它们在文本输入和输出不是最佳的场景中的应用。虽然最近的进展(例如 GPT4o)引入了极低延迟的语音交互功能,增强了用户体验,但开源社区在基于 LLM 的语音交互模型构建方面仍需要全面探索。研究人员正在努力解决的紧迫挑战是如何利用 LLM 实现低延迟和高质量的语音交互,从而扩大其在不同使用场景中的可访问性和适用性。
人们尝试了多种方法来实现语音与 LLM 的交互,但每种方法都有局限性。最简单的方法涉及使用自动语音识别 (ASR) 和文本转语音 (TTS) 模型的级联系统。然而,这种顺序方法会导致更高的延迟,因为需要逐步处理转录文本、文本响应和语音响应。人们还提出了多模态语音语言模型,将语音离散化为标记并扩展 LLM 词汇表以支持语音输入和输出。虽然这些模型理论上允许以低延迟直接生成语音到语音,但实际实施通常涉及生成中间文本以保持更高的质量,从而牺牲一些响应速度。其他尝试包括在语义或声学标记上训练语言模型、联合训练语音标记和文本以及向 LLM 添加语音编码器。然而,这些方法通常需要大量数据和计算资源,或者只关注语音理解而没有生成能力。
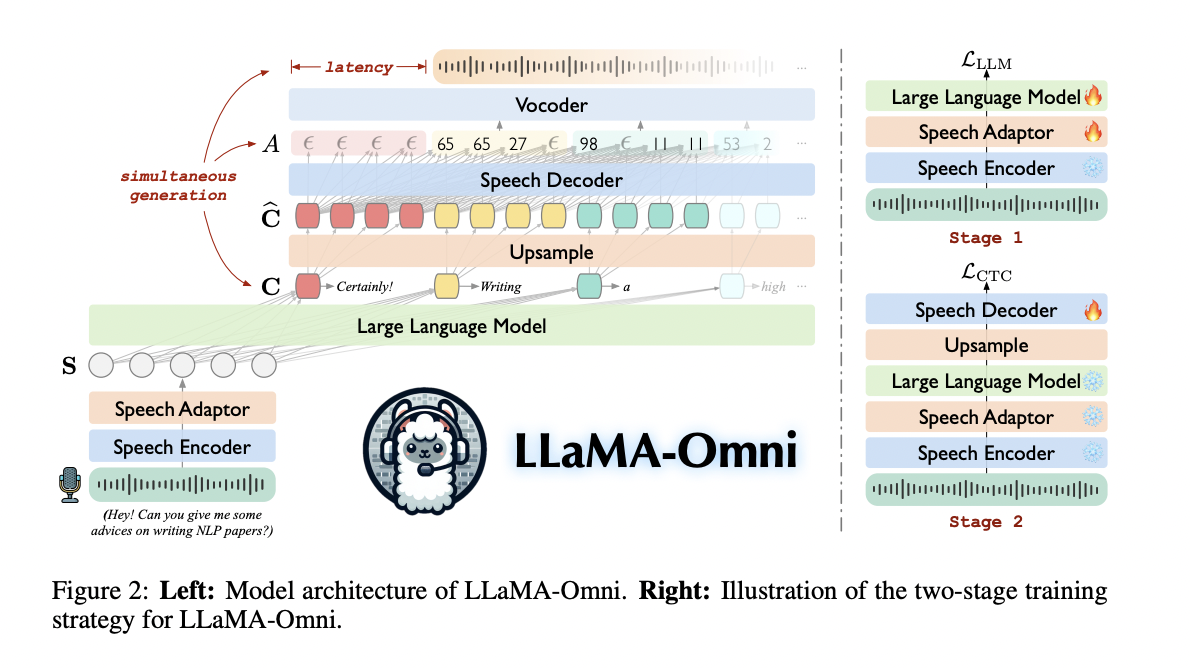
中国科学院大学的研究人员提出了一种创新的模型架构*LLaMA-Omni*,旨在解决使用 LLM 实现低延迟和高质量语音交互的难题。这种创新方法集成了语音编码器、语音适配器、LLM 和流式语音解码器,实现无缝的语音到语音通信。该模型直接通过编码器和适配器处理语音输入,然后将其输入到 LLM,从而无需中间文本转录。非自回归流式 Transformer 充当语音解码器,利用联结主义时间分类来预测与语音响应相对应的离散单元。这种架构可以同时生成文本和语音输出,大大减少了响应延迟。为了支持该模型的开发和评估,研究人员创建了专门针对语音交互场景量身定制的 InstructS2S-200K 数据集。

LLaMA-Omni 的架构由四个主要组件组成:语音编码器、语音适配器、LLM和语音解码器。语音编码器基于 Whisper-large-v3,从用户的语音输入中提取有意义的表示。然后,这些表示由语音适配器处理,语音适配器通过下采样和两层感知器将它们映射到 LLM 的嵌入空间中。LLM 基于 Llama-3.1-8B-Instruct,可直接从语音指令生成文本响应。语音解码器是一种非自回归流式 Transformer,它采用 LLM 的输出隐藏状态并使用联结时间分类 (CTC) 来预测与语音响应相对应的离散单元。
该模型采用两阶段训练策略。在第一阶段,它学习根据语音指令生成文本响应。第二阶段专注于生成语音响应,只训练语音解码器。在推理过程中,LLaMA-Omni 同时生成文本和语音响应。当 LLM 生成文本时,语音解码器生成相应的离散单元,然后实时转换为语音波形。这种方法可以实现极低延迟的语音交互,用户能够在生成完整文本之前听到响应。
InstructS2S-200K 数据集是为了训练 LLaMA-Omni 进行语音交互而创建的。它由 200,000 个三元组组成,包括语音指令、文本响应和语音响应。构建过程包括使用 Llama-3-70B-Instruct 重写语音的文本指令、生成适合语音的简洁响应,以及使用 CosyVoice-300M-SFT 合成语音指令和 VITS 合成响应。该数据集结合了来自 Alpaca 的 50,000 个条目和来自 UltraChat 的 150,000 个条目,涵盖了各种主题。这个专门的数据集为训练 LLaMA-Omni 进行基于语音的任务提供了坚实的基础,确保自然而高效的交互。
InstructS2S-Eval 基准测试的结果证明了 LLaMA-Omni 在语音交互任务中的表现优于之前的模型。它在语音转文本和语音转语音教学的内容和风格方面都表现出色,实现了语音和文本响应之间的更好一致性。该模型在语音质量和响应延迟之间实现了权衡,延迟低至 226 毫秒。与其他模型相比,LLaMA-Omni 同时生成文本和语音可显著缩短解码时间。案例研究表明,LLaMA-Omni 提供了更简洁、更详细、更有用的响应,适合语音交互场景,在这方面的表现优于之前的模型。
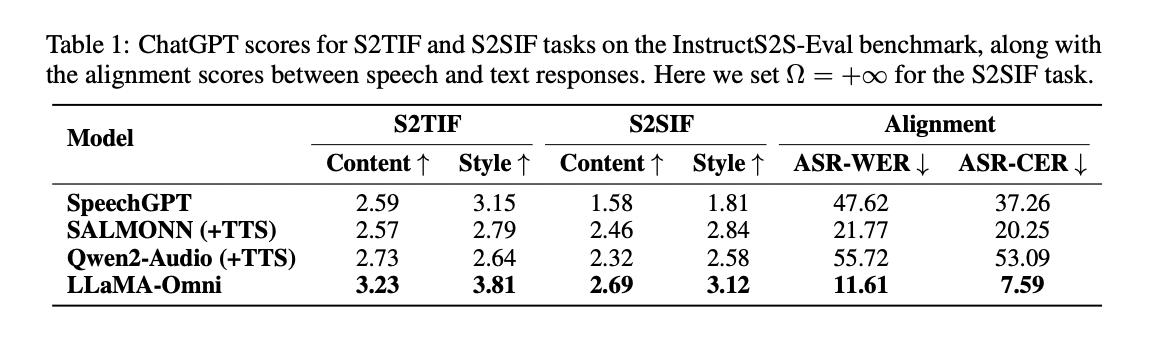
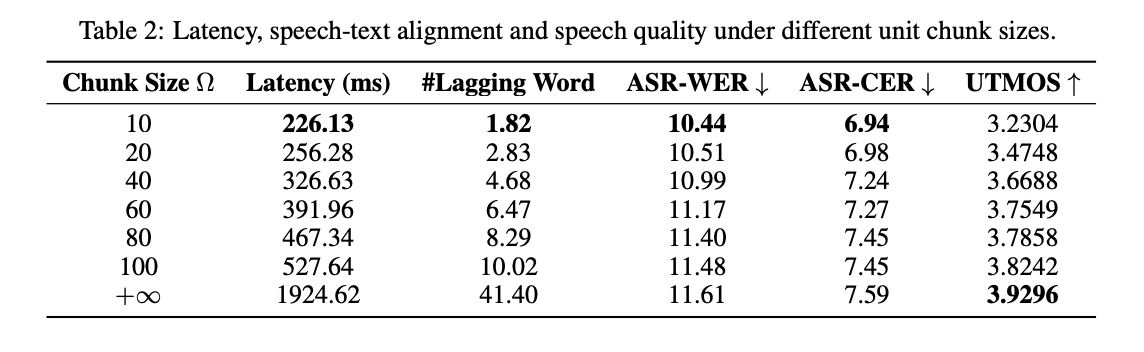
LLaMA-Omni 是一种创新的模型架构,旨在实现高质量、低延迟的 LLM 语音交互。LLaMA-Omni 以 Llama-3.1-8B-Instruct 模型为基础,集成了用于理解的语音编码器和用于同时生成文本和语音响应的流式语音解码器。该模型与语音交互场景的契合是通过创建包含 200,000 条语音指令和响应的数据集 InstructionS2S-200K 实现的。实验结果表明,与现有的语音语言模型相比,LLaMA-Omni 在内容和风格方面均表现出色,响应延迟极低,仅为 226 毫秒。该模型的高效训练过程在 4 个 GPU 上仅需不到 3 天的时间,有助于快速开发基于尖端 LLM 的语音交互模型。
模型地址:https://modelscope.cn/models/ICTNLP/Llama-3.1-8B-Omni