Ollama Lora微调
Ollama Lora微调
选择基础模型
基础模型使用的是Chinese-Mistral-7B-Instruct-v0.1,没有这个模型的可以去https://huggingface.co/,或者huggingface镜像网站,或者魔搭社区进行下载,我用魔搭社区的python脚本进行下载。
下载模型
新建一个download.py脚本
from modelscope import snapshot_download
#模型存放路径
model_path = '/root/autodl-tmp'
#模型名字
name = 'itpossible/Chinese-Mistral-7B-Instruct-v0.1'
model_dir = snapshot_download(name, cache_dir=model_path, revision='master')
选择数据集
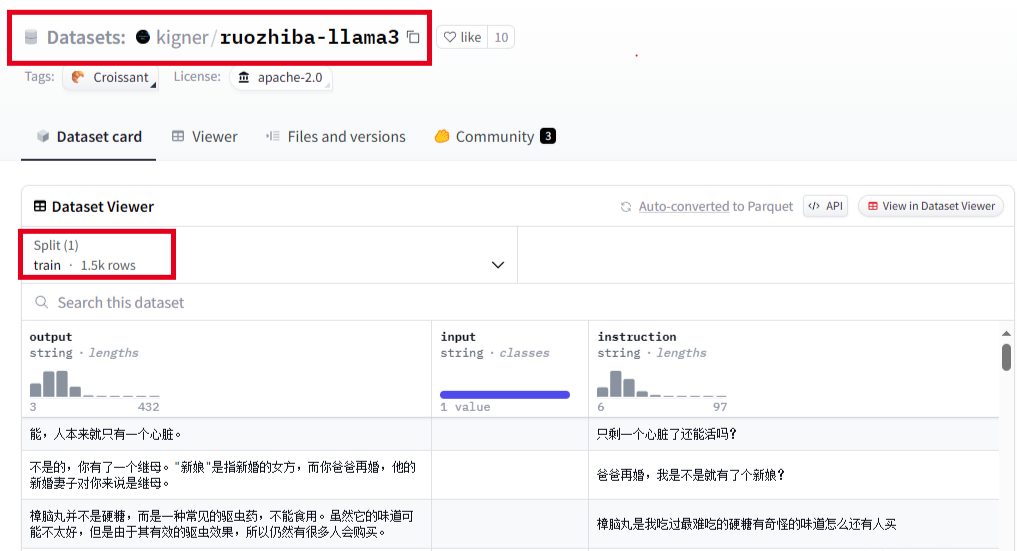
微调大模型要想获得比较好的效果,拥有高质量的数据集是关键。可以选择用网上开源的,或者是自己制作。以中文数据集弱智吧为例,约1500条对话数据,数据集可以从https://huggingface.co/,或者huggingface镜像网站HF-Mirror – Huggingface 镜像站进行下载。我是手动下载后,上传到服务器。
LORA微调
安装依赖
我是miniconda创建的python环境,python版本=3.10。
依赖文件requirements.txt内容如下:
transformers
streamlit==1.24.0
sentencepiece==0.1.99
accelerate==0.29.3
datasets
peft==0.10.0
pip install - r requirements.txt
训练脚本
from datasets import Dataset
import pandas as pd
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
DataCollatorForSeq2Seq,
TrainingArguments,
Trainer, )
import torch,os
from peft import LoraConfig, TaskType, get_peft_model
import warnings
warnings.filterwarnings("ignore", category=UserWarning) # 忽略告警
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 模型文件路径
model_path = r'/root/autodl-tmp/itpossible/Chinese-Mistral-7B-Instruct-v0.1'
# 训练过程数据保存路径
name = 'ruozhiba'
output_dir = f'./output/Mistral-7B-{name}'
#是否从上次断点处接着训练
train_with_checkpoint = True
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
#加载数据集
df = pd.read_json(f'./dataset/{name}.json')
ds = Dataset.from_pandas(df)
print(ds)
# 对数据集进行处理,需要将数据集的内容按大模型的对话格式进行处理
def process_func_mistral(example):
MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性
instruction = tokenizer(
f"<s>[INST] <<SYS>>\n\n<</SYS>>\n\n{example['instruction']+example['input']}[/INST]",add_special_tokens=False) # add_special_tokens 不在开头加 special_tokens
response = tokenizer(f"{example['output']}", add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1] # 因为pad_token_id咱们也是要关注的所以 补充为1
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
if len(input_ids) > MAX_LENGTH: # 做一个截断
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
inputs_id = ds.map(process_func_mistral, remove_columns=ds.column_names)
#加载模型
model = AutoModelForCausalLM.from_pretrained(model_path, device_map=device, torch_dtype=torch.bfloat16, use_cache=False)
print(model)
model.enable_input_require_grads() # 开启梯度检查点时,要执行该方法
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # 训练模式
r=8, # Lora 秩
lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理
lora_dropout=0.1 # Dropout 比例
)
model = get_peft_model(model, config)
model.print_trainable_parameters()
args = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=2,
gradient_accumulation_steps=2,
logging_steps=20,
num_train_epochs=2,
save_steps=25,
save_total_limit=2,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True
)
trainer = Trainer(
model=model,
args=args,
train_dataset=inputs_id,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
# 如果训练中断了,还可以从上次中断保存的位置继续开始训练
if train_with_checkpoint:
checkpoint = [file for file in os.listdir(output_dir) if 'checkpoint' in file][-1]
last_checkpoint = f'{output_dir}/{checkpoint}'
print(last_checkpoint)
trainer.train(resume_from_checkpoint=last_checkpoint)
else:
trainer.train()
将checkpoint转换为lora
新建一个checkpoint_to_lora.py,将训练的checkpoint保存为lora
from transformers import AutoModelForSequenceClassification,AutoTokenizer
import os
# 需要保存的lora路径
lora_path= "/root/lora/Mistral-7B-lora-ruozhiba"
# 模型路径
model_path = '/root/autodl-tmp/itpossible/Chinese-Mistral-7B-Instruct-v0.1'
# 检查点路径
checkpoint_dir = '/root/output/Mistral-7B-ruozhiba'
checkpoint = [file for file in os.listdir(checkpoint_dir) if 'checkpoint-' in file][-1] #选择更新日期最新的检查点
model = AutoModelForSequenceClassification.from_pretrained(f'/root/output/Mistral-7B-ruozhiba/{checkpoint}')
# 保存模型
model.save_pretrained(lora_path)
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# 保存tokenizer
tokenizer.save_pretrained(lora_path)
合并模型
新建一个merge.py文件,将基础模型和lora模型合并为一个新的模型文件
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from peft import PeftModel
from peft import LoraConfig, TaskType, get_peft_model
model_path = '/root/autodl-tmp/itpossible/Chinese-Mistral-7B-Instruct-v0.1'
lora_path = "/root/lora/Mistral-7B-lora-ruozhiba"
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 合并后的模型路径
output_path = r'/root/autodl-tmp/itpossible/merge'
# 等于训练时的config参数
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # 训练模式
r=8, # Lora 秩
lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理
lora_dropout=0.1 # Dropout 比例
)
base = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True)
base_tokenizer = AutoTokenizer.from_pretrained(model_path)
lora_model = PeftModel.from_pretrained(
base,
lora_path,
torch_dtype=torch.float16,
config=config
)
model = lora_model.merge_and_unload()
model.save_pretrained(output_path)
base_tokenizer.save_pretrained(output_path)